
This article is part one in a month-long series aimed at learning and exercising the RingCentral APIs in Python as part of their new Game Changers challenge. Feel free to follow along, leave a comment, or even participate in the challenge yourself!
The second component we need to start setting up for our virtual voicemail assistant is a brain. Essentially, we need a way for the computer to understand incoming messages, extract meaningful keywords from content, and let us know when something interesting happens. As with the original tutorial, we're going to set up an account with MonkeyLearn and leverage their API.
Once you've created an account and verified your email, you'll be ready to get started building a classification engine. For the purposes of this walk-through, we're going to leverage some of the default models already available through the platform. If you want a more sophisticated model it's usually a good idea to harvest your own content and hand-categorize it. This will help the model train to recognize content matching your business case more accurately.[ref]If you're also building a virtual voicemail assistant, my recommendation would be to transcribe and hand-label as many existing voicemail messages as possible. This will increase the machine's ability to understand content addressing your business, as well as frequent concerns raised by your customers.[/ref]
[caption id="attachment_8119" align="aligncenter" width="1216"]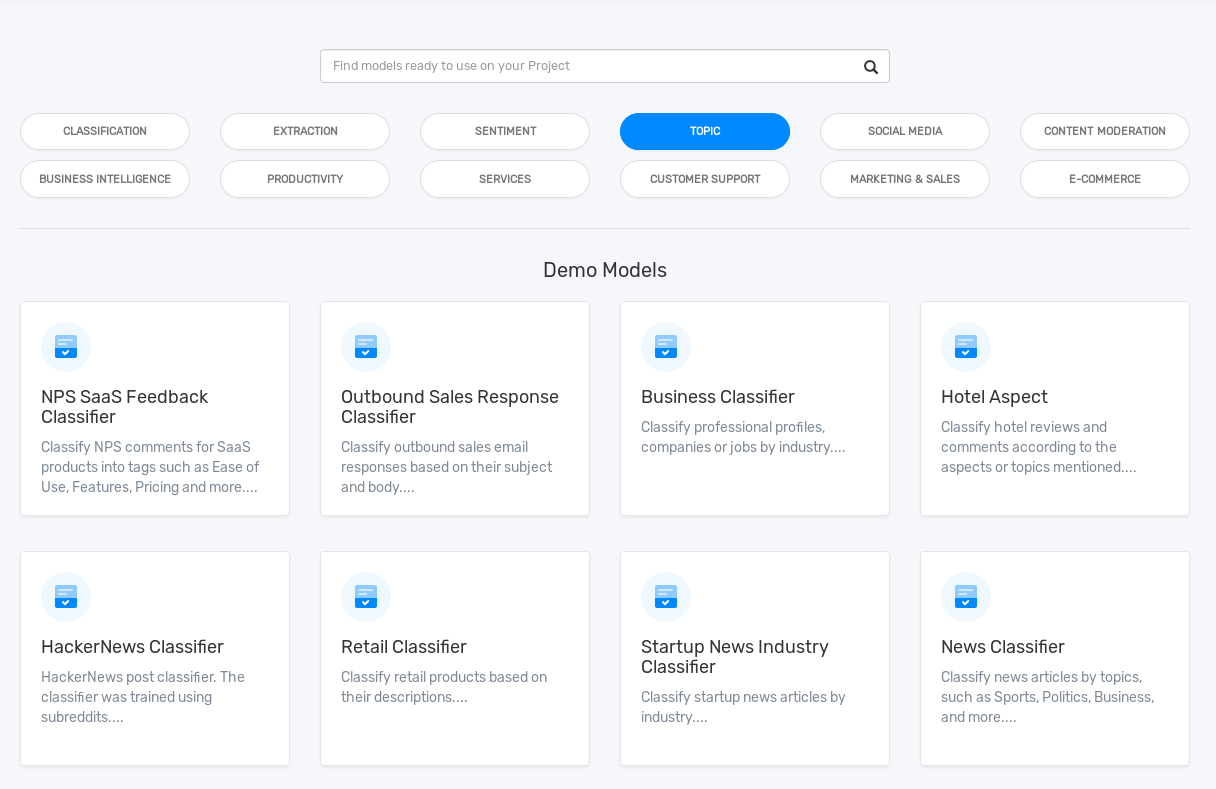 Default model selection dashboard.[/caption]
Default model selection dashboard.[/caption]
Again, we'll do a few things differently for this walk-through than we will when building our full virtual assistant. Namely, our sandbox account with RingCentral isn't transcribing messages for us (we either need a paid account for that or will need to leverage an outside service). Instead, we'll leverage the MonkeyLearn API to extract topics from some already-in-text-format content. Namely, some of the content on this blog![ref]I realize it's is a trivial example to leverage machine learning to categorize a blog, but it's a good way to exercise the API as we learn it as well.[/ref]
Topic Classification
Since we're using this blog as a sample to test the API, we're going to leverage the already-trained HackerNews Classifier to try selecting some topics for content on the site. To get started, let's grab some random posts from my somewhat recent history and copy the content into the MonkeyLearn UI. I'll list each post and the categories and confidence the classifier identified in bold:
- Context Managers in PHP - "programming" 100%
- Open Letter to the Democratic Party of Washington County - "science" 31.4%[ref]This result was somewhat expected. The classifier is specifically trained to only produce the labels of business, design, entertainment, programming, science, security, and world news. I threw this article in here because, honestly, it doesn't fall into any of those categories and I wanted to see what would happen.[/ref]
- Software Vulnerabilities, Disclosure, and Marketing - "security" 95.8%
- Deterministic Random Numbers in PHP - "programming" 92.2%
- Managing Gearman Securely - "programming" 94.3%
API Access
We obviously won't be pasting a transcript of every phone call into a classifier, so let's take a look at the API we can use. MonkeyLearn ships with an excellent Python SDK to make accessing the API programmatically super easy. First we just install the system:
pip install monkeylearn
Then we leverage the SDK, along with our (secret) API key, to classify text according to the classifier we picked earlier:
from monkeylearn import MonkeyLearn
import pprint
ml = MonkeyLearn('API_KEY_GOES_HERE')
data = ["This article is part one in a month-long series aimed at learning and exercising the RingCentral APIs in Python as part of their new Game Changers challenge. Feel free to follow along, leave a comment, or even participate in the challenge yourself!"]
model_id = 'cl_GLSChuJQ'
result = ml.classifiers.classify(model_id, data)
pp = pprint.PrettyPrinter(indent=4)
pp.pprint(result.body)
The output of this is printed cleanly by the Python code to demonstrate the return of the API and the classification provided by the model.
[caption id="attachment_8122" align="aligncenter" width="814"]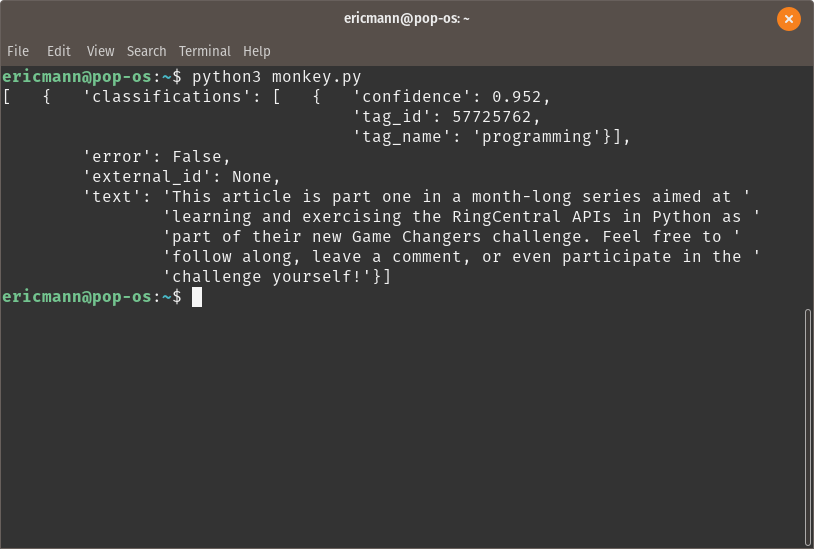 MonkeyLearn API Response[/caption]
MonkeyLearn API Response[/caption]
Next Steps
This pattern gives us everything we need to automatically extract categories, sentiment, and other classifications from text-based content as it comes in through our virtual assistant. We can start coding a Python server to listen for webhook calls from RingCentral so we can act on them immediately. As I mentioned earlier, though, our current sandbox setup doesn't feature automated transcription. Our next step will be to flesh out a text-to-speech system so we can programmatically work with the content of any incoming messages!